BLIP

简单记录
参考:https://www.cnblogs.com/theseventhson/p/18488142
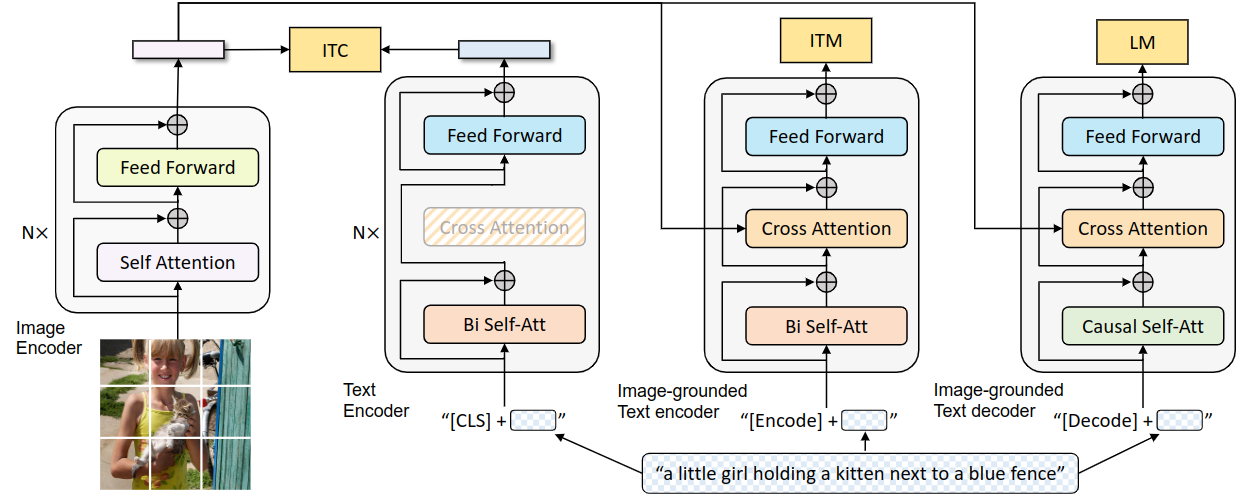 一种VLM,使用编码器-解码器混合架构MED
一种VLM,使用编码器-解码器混合架构MED
视觉编码器:提取图片特征
ViT架构
- 图像分割
- CLS(记录总结性信息的)
- 得到image embedding
文本编码器:提取文本特征(理解)
Bert架构
双向self-attention:前后token都可以“看见”,然后预测(主-理解)
CLS
得到text embedding
ITC:对比学习,对比image、text的embedding,匹配则更近
动量模型
视觉文本编码器
- cross-attention:将text与image embedding混起来了
- [Encode] token
视觉文本解码器:预测下一token
causal self-attention:针对生成任务,model只能“看到”前文(主-生成)
他这里也是用bert,是因为要参数共享,其中会根据encoder or decoder来判断mask的方式
可以将bert看作“共享骨架”
1
is_decoder=true时,会激活cross-attention模块,并且进行的是“预测”,LM
[Dncode] token、结束token
nucleus sampling
相同颜色的部分是参数共享的,即视觉文本编码器和视觉文本解码器共享除 Self-Attention 层之外的所有参数。每个 image-text 在输入时,image 部分只需要过一个 ViT 模型,text 部分需要过3次文本模型
预训练目标
包含3个,这里重点关注“生成任务”
语言模型目标函数ML
根据前文+image编码特征,经过视觉文本编码器得到条件概率P。
在视觉文本解码器中,image编码特征通过cross-attention注入到每一layer:
$$
LM=−∑logP_θ(y_t∣y_{<t},image)
$$
1 | self_attn(y_{<t}) + cross_attn(v_image) |
这样就实现了条件生成(以image作为条件)
data
也是BLIP的一大创新点,但和我现在关注的问题关联不大,就先不管了
代码
VisionTransformer
A PyTorch impl of : An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
PatchEmbed是 视觉 Transformer 的“tokenizer”:
它把一张二维图片分割成多个固定大小的 patch,并将每个 patch 线性投影成 embedding,输出一串 token 序列供 Transformer 处理。
在所有patch前面加上了[CLS],该向量就携带了整个image的信息
1
2输入序列:[CLS] + patch_1 + patch_2 + ... + patch_N
位置编码
1
x = x + self.pos_embed[:,:x.size(1),:]
self-attention(block*n)
视觉文本解码器
使用bert实现了类似GPT的自回归语言建模
- Author: dawn_r1sing
- Created at : 2025-11-06 20:05:53
- License: This work is licensed under CC BY-NC-SA 4.0.(转载请注明出处)