机器学习

简单记录:B站机器学习-李宏毅
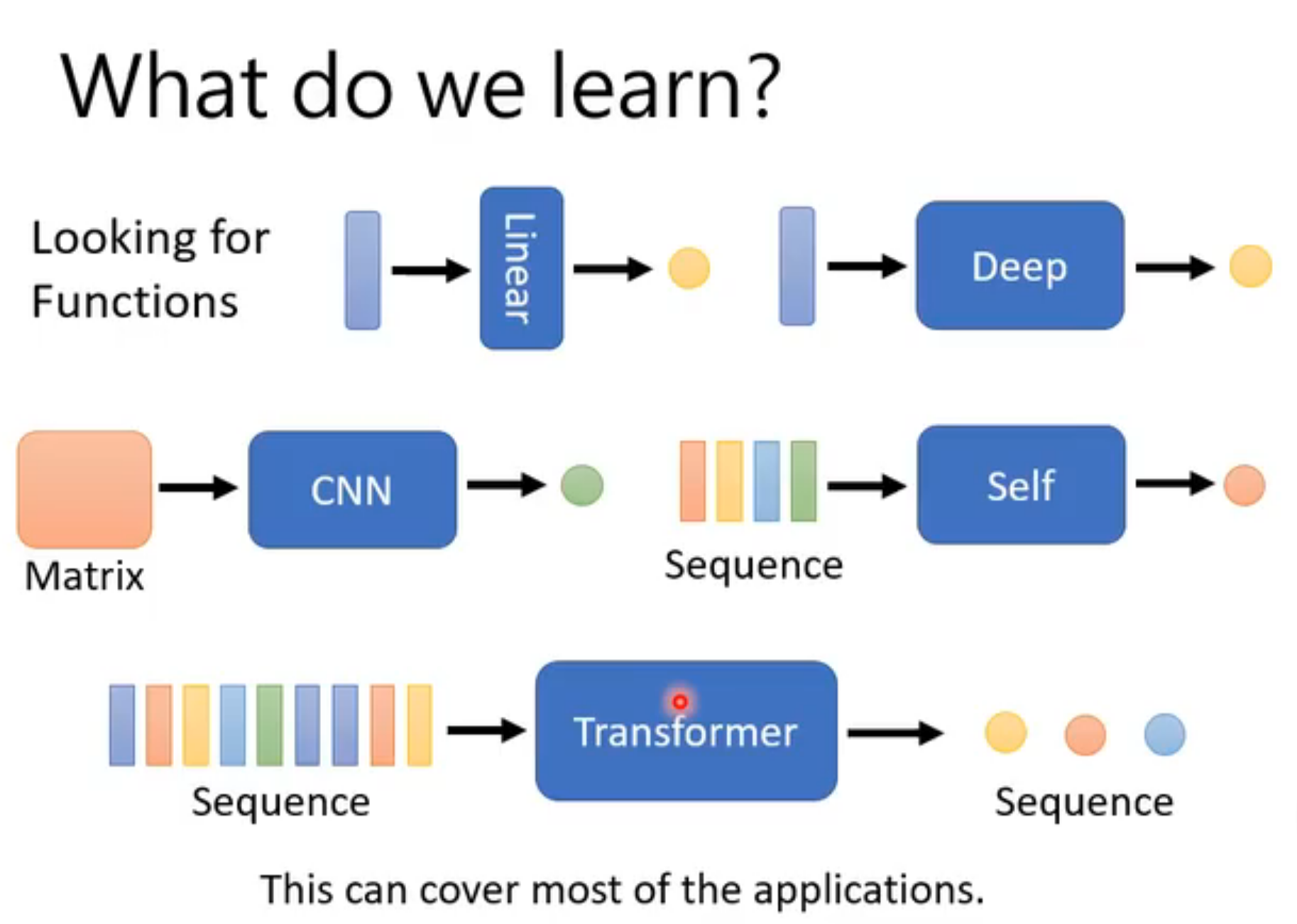
model
流程
training
对于pic,可以先经过edge detection……
确定有未知数的function,未知参数h - 取值空间H
- |H| 为复杂度 == 选择的function数目
定义loss
- 需要资料计算
(x, y)=> D_train - 整个资料集的错误率cross-entropy (loss function):
L( h, D_train )
- 需要资料计算
进入epochs
optimization
找最优function的过程,不断调整w、b
最优参数:h* = arg min L(h, D_train)
优化算法
- SGD
- Adam
我们希望
L(h_train,D_all) -L(h_all,D_all) <= δ
对于loss而言
- N 越大越好
- |H| 越小越好。但由于|H|很小,此时在D_all上计算的loss并不准确,即使此时loss很小、和D_all上计算的loss很接近
validation
为了防止出现overfitting的现象,我们在训练过程每个epoch最后阶段使用验证集检查loss是否开始上升
如果开始上升,我们需要调整超参数或停止训练
Validation set:D_val(development data)
- 过程:
- 使用模型计算D_val的loss
- 若loss开始开始上升,则说明可能发生overfitting,需要采取一些措施(如Reinforcement Learning……)或者及时止损
- overfitting
- H - 待选model数:太多可能导致overfitting
testing
1 | Model |
概念讨论
batch
- small batch v.s. large batch
- large batch
- 方差小,noisy小,容易停滞
- 由于平行运算,一定程度上计算时间差不多;但还是有限的
- large batch会导致正确率下降
- small batch
- 方差大,noisy大,一般来说比较分散
- noisy 可以一定程度上缓解saddle point
- small batch有利于testing
- 一周期时长长
- large batch
critical point
一阶导数为0
local minima 局部最小、saddle point 鞍点
hasson = 二阶导数矩阵 → 确认critical point种类
- 特征值有正有负 → saddle point → 向负特征值对应的特征向量移动
hyperparameter
人所设定的参数,不是机器决定的
Loss function
error surface
根据model预测结果和实际结果做差得到的loss图
- 三维
- 等高线(和地理思路相同,陡 - 说明loss对于某参数的变化很敏感)
supervised learning
有label
学习和预测,回答有标准答案的问题
classification
预测离散的类别标签(如判断正误,判别种类)
- 真实值y是0/1串
- softmax(pre_y) 与 y 越接近越好
pre_y获得方法
1. softmax
类似将计算值normalize后获得一串pre_y,然后再进行比较
多个class
输入:logit(类似一个分类评分
输出:介于0-1之间(类似概率值、连续
logit → (exponential) → 中间值(正) → (normalize) → pre_y
可以放大差距
Σpre_y = 1
2. sigmoid
(3. arg max获得离散类别)
regression
预测连续型数值(如预测播放量、房价等)
- pre_y 和 y 越接近越好
loss function
- MSE - 求差的平方和
- 更多用在regression
- cross-entropy - 交叉熵
- classification更常用
- 原因:从optimization角度,避免了梯度消失(loss_function求导发现仅取决于预测值与真实值的差距),更有利于后续优化的进行(否则在很平坦的地方他就跑不动了),对loss更敏感,迫使模型修正
Optimization
帮你改未知参数,update
Gradient Descent
计算gradient,向其反方向移动参数
Loss计算:
- gradient :损失函数对所有未知参数求微分,使用g更新参数,表示梯度
- g在每个batch中更新(在一个批次的数据中求微分),处理完所有batch为一个周期epoch
- learning rates
- θ :影响参数,θ* 最佳参数

Root Mean Square(RMS)
loss不再下降时,并不意味着gradient == 0
training stuck ≠ small gradient → 优化有问题 → 客制化learning rate
σ = 所有gradient平方和的均值,开根号
lr = lr / σ
对于一个参数:
- 陡峭,gradient大,σ大,lr小,步长小
- 平缓,gradient小,σ小,lr大,步长长
不足:
- 随着训练的进行,σ会不断增大(越后期,变化越慢,甚至基本不变)
- 求解历史g平方均值,使得历史g的权重较大,无法适于新的梯度变化
- 在训练初期,参数变化较大,导致梯度可能会有较大的波动性
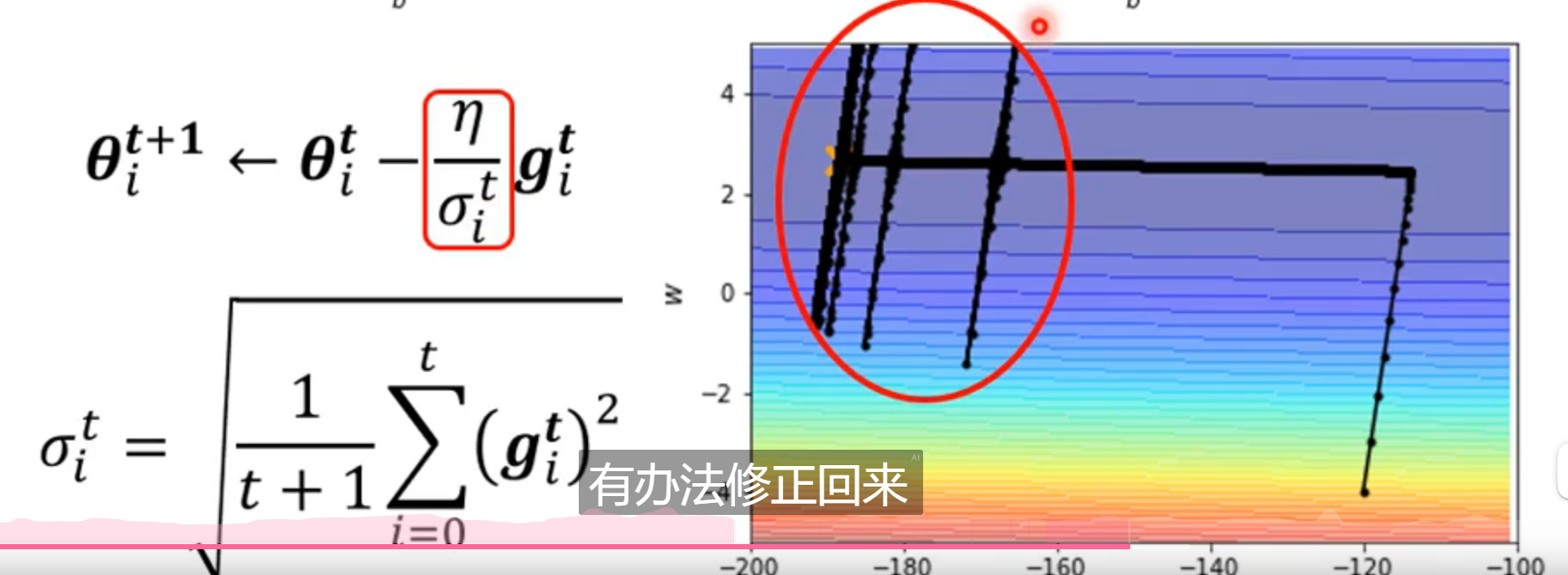
上图出现的原因:
在纵轴方向上,前部分训练过程的g比较大,等到后面逐渐变小。由于是做平均数,当小的g逐渐积累、平均,最终导致某时刻的σ变得很小,此时纵轴方向的lr变大,因此会突然跑出去
后期由于g较大,σ又变大,lr变小,步子变小。
learning rate scheduling
- learning rate decay → 随着时间的推移,逐渐减小lr(逐渐接近终点,看作不断在刹车)
- warm up → lr先增大,在减小
进阶版 - Adam
= RMSProp + momentum
- RMSProp(油门+刹车) => 步伐长短
动态调整lr,lr随着gradient、时间而变化(调整α
- momentum(惯性) => 方向
向 前一步移动方向 - gradient方向 的反方向移动
normalization
change landscape,令error surface不崎岖
batch normalization、……
将 feature vector 中同dimension的x标准化,令均值为0
每一层之间对输入也进行一次normalization
- activation function之前或之后进行normalization都可以
而实做过程中,我们使用一个batch作为输入进行normalization
问题:
- internal covariate shift ?似乎并没有这个问题
network
activation function
σ(w1x1+w2x2+……)这就是一个neural做的事情,会有许多参数w_i,其中σ就是activation function
piecewise linear
- 非线性激活函数
- 可以逼近任何的function
- 逼近 Hard Sigmoid(阶梯型)
- 多个Sigmoid加和逼近实际Function(一个hidden layer)
- 对于一个Sigmoid可以反复求Sigmoid(deep),但过深会导致过拟合
多个ReLU合成Hard Sigmoid (形状: ___/ )

深度学习
可实现 loss小 + 与现实接近
deep v.s. fat
one hidden layer(fat)可以表示任何function
deep结构更有效,使用参数更少(减少overfitting的可能)(指数级)
复杂且有规律的 → deep更有优势 e.g.image、video
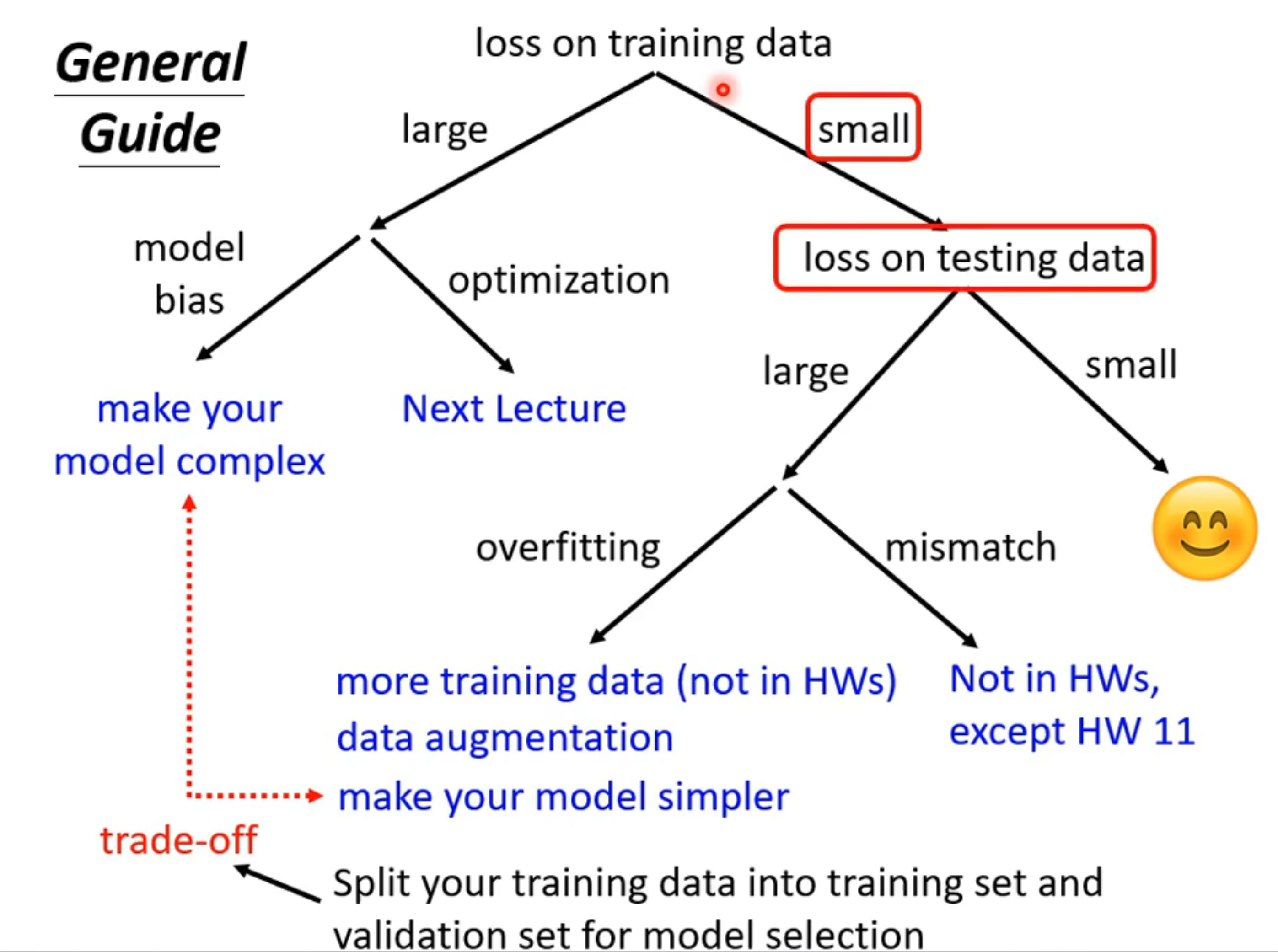
model分析
training models的loss太大
- model bias v.s. optimization
model bias
- 修改model:增加features
optimization
- 换更好的算法
区分:使用浅model和深model,对比计算train和test数据的loss
testing models的loss太大
overfitting v.s. ()
overfitting:
P(D_train is bad) <= |H|*2exp(-2Nε^2)- 增加training data - N(真实或猜测新的training数据 → 放大缩小左右翻转)
- 限制 model - H(model弹性不要太大 = complication不要太大 = 可能的function不要太多 = 未知参数取值可能性不要太多
- 减少参数
- dropout(随机临时丢弃neural
- ……
layer
层与层neural之间的连接形式
FC层
fully connected
- 每一个neural都会和前一层的neural相连
- 可以逼近任何函数
- 参数量大
卷积层
- 一组neural(filter)与一个field进行连接
- neural进行平移,也就是参数共享
CNN
(卷积神经网络 convolutional neural network)
主要处理图片 + 下围棋AlphaGo
还有语音、影像
输入:向量
输出:类别
过度简化(pooling)导致model bias比较大
可能无法分辨放大、缩小、旋转的图片(因为向量变化了)→ 所以我们可以往sample中加一些放大和缩小后的图片
流程:
- convolution 和 pooling 交替使用 (随着计算能力的提升,pooling的使用逐渐减少)
- 通过flatten操作将pic拉直,作为fully connected layers的输入,之后再将结果过一遍softmax,完成classification
convolution
一组filter扫描一遍图片
receptive field
将图片分块
receptive field设定方式为
all channel * (3*3)一组 neural(大概64,即64个filter)接受一个receptive field
水平、竖直移动长度stride,希望不同的receptive field会重叠。
超出范围padding补值
所有数据全部覆盖
参数共享
对于审查不同field但审查功能相同的neural(filter),可以让他们共享参数,实现simplify
相当于neural是成套的,每一个field分配一套neural
类似学校发练习册,每个学生学习内容是一样的,因此练习册也完全可以是一样的,没有必要给每个人都量身定制一本不一样的练习册,对应这里就是:对于每一个field,既然做的检查项目都是一致的,那对应的一整套参数也完全可以设计成一致的,实现simply
具体体现:每次卷积操作中,将一组filter进行平移
pooling
由于计算能力有限,我们会将image进行模糊化(让数据量减小)
maxpooling :当获取到filter的output后,取块x*x中的最大值代替整个field
……
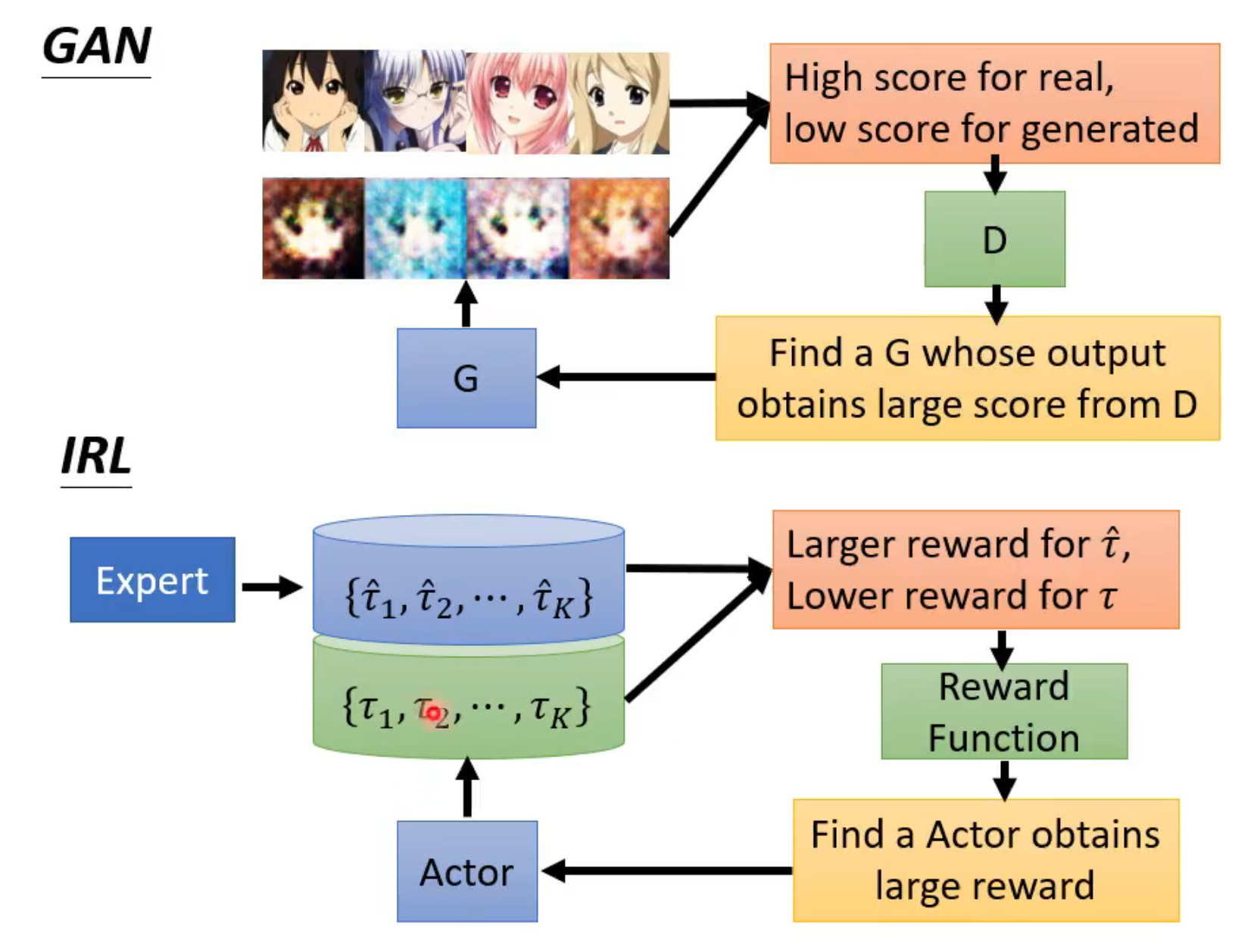
生成式对抗网络 GAN
生成,回答开放性问题
GAN
→ generative models
- 输入:random simple distribution(可sampling)
- 输出:complex distribution(可sampling),有多种可能的输出 → 富有创造性
- 有很多变形
- generator + discriminator(鉴别器)
流程
自己卷自己
- 初始化generator和discriminator
- 将向量输入给generator,output与dataset一起输入给discriminator进行对比分辨,输出分数(训练discriminator)
- 将分数输回generator,反复
理论
P_G:generator生成的distribution
P_data:真实的distribution(data set)
让divergence越小越好 → argminDiv(P_G, P_data)(就像loss function)→ 只需要sampling采样就可以估计出divergence
→ argmaxV(D, G) ≈ JS divergence → argmin maxV(D, G)
训练技巧
GAN很难train
JS divergence的问题:
- P_G, P_data是高位空间中在低维空间中的manifold,重叠范围非常小
- 对于两个没有重叠的distributions,JS divergence == log2,所以一般情况下基本没有变化,此时无法进行有效的generator的训练
WGAN
Wasserstein distance (替代JS divergence
将P分布moving成Q分布,穷举找到最小的moving plan
1 | max{E_data[D(y)] - E_G[D(y)]}, D为平滑distribution |
conditional GAN
输入:x,random simple distribution
输出:distribution
- discriminator输入:(描述x,图片)对
pixtopix
输入x、image,生成image(e.g.输入房子草图,生成房子真实图 / 输入声音,生成影像
supervised → 输出模糊
GAN → 想象力过丰富
supervised + GAN → 更优
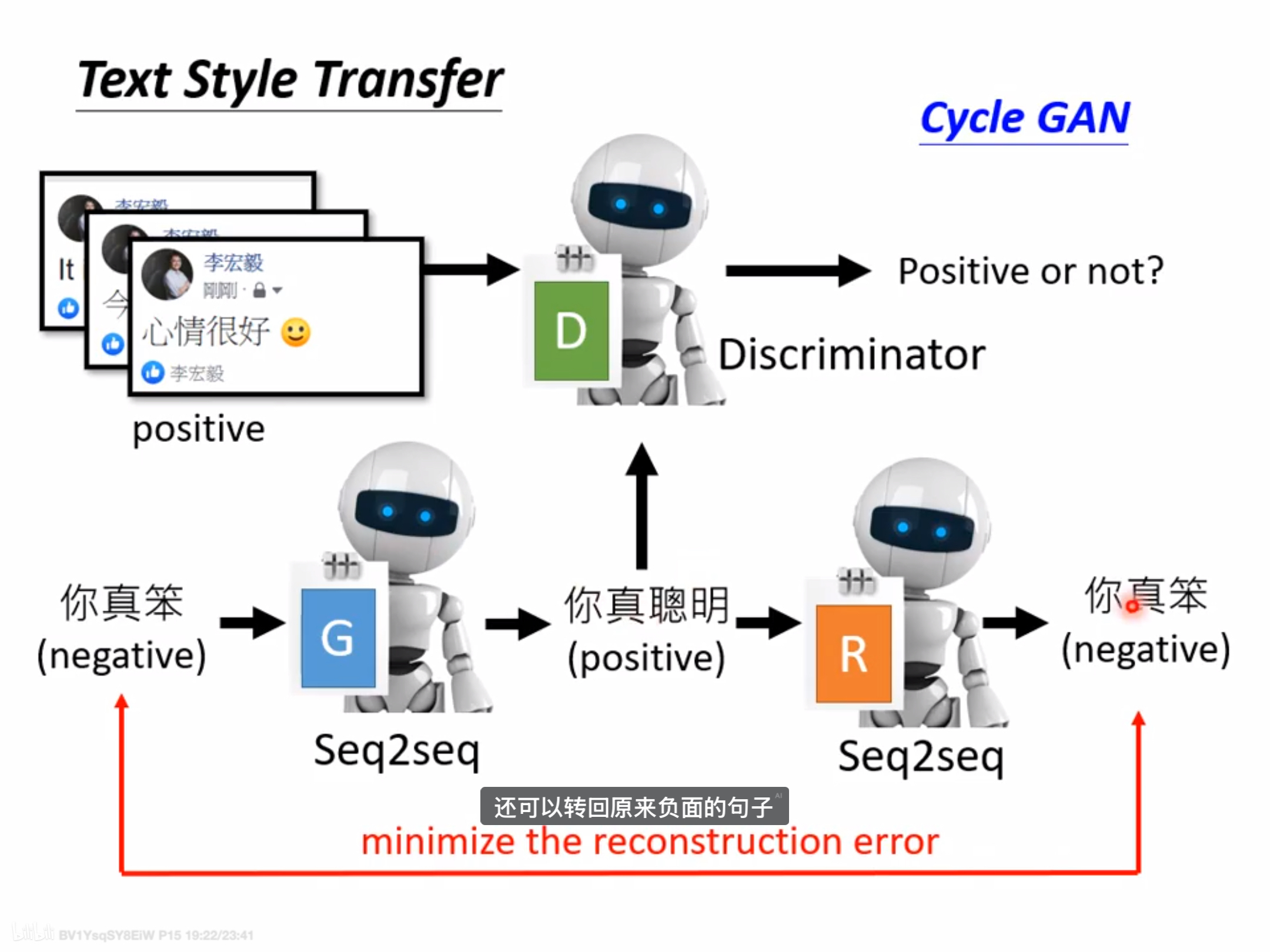
Cycle GAN(unsupervised)
application:learning from unpaired data
e.g. 影像风格转换、文字风格转换
- 输入:
- 问题是如何让generator不忽视输入
过程:
- 输入与进行两次转换之后的输出越接近越好
- 同时discriminator判断generator一次转换的output是否为“二次元”类
问题:
- 学习到的特征转换很奇怪(现实中比较少)
类似的:StarGAN
评估
人工
使用分类系统(CNN),越集中,可能说明generator比较好
mode collapse - 没有diversity,此时classification结果好,也并不意味着generator性能好
mode dropping - 不易发现的low diversity
- 同一输入的输出classification结果好,大量输入的输出均值classification很平均
=> IS → good quality + large diversity
FID:使用softmax之前的输出向量进行评估,比较两组的Gaussian distance,计算FID
- 并不完全是Gaussian
- 大量samples
生成和train中相同的images
Self-attention
计算机制
内部元素之间的attention机制
处理input是一个sequence的情况,即输入一串有序序列、sample之间有关联
输入:
文字 → vector
- one-hot encoding(没有语义信息)
- word embedding(将离散数据映射到连续的空间上)
音频
- 一小段音频 → frame
- 移动frame
graph / 分子
- 每个节点可以看做一个vector
输出:
- one vector to one label - sequence labeling
- each vector to one label: sentiment analysis……
- 未知数目的label:语音辨识
- 应用:transformer
- 计算量大
过程
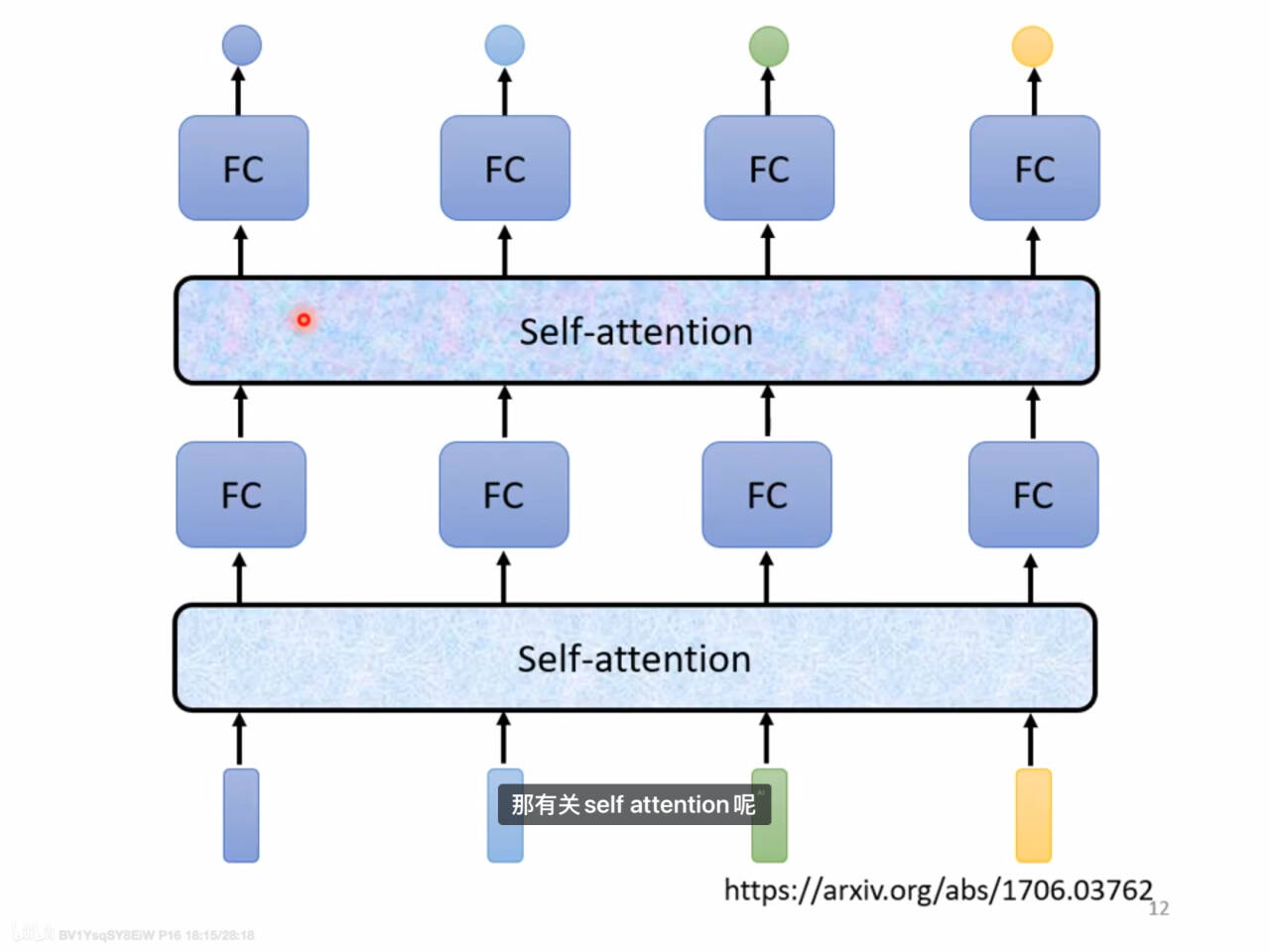
法1
在Self-attention中,each output取决于所有input
通过线性变换获得key和q两个矩阵(乘以输入矩阵的W_Q、W_K矩阵内容是可以训练的,也是multi的)
Query(Q):当前 token 希望获取的信息向量矩阵。
Key(K):所有 token 的信息向量
qkey得到*当前输入vector对key中每一个信息的score,即输入vector a与所有vector的关联性α
softmax获得概率分布进行归一化(activate function),获得权重 α‘
即可确定哪些vector和a更有关联性
获得第i个输出
法2
简化计算,计算output时只需要改q

优化
重点在于n*n的矩阵乘法计算的优化
当sequence相当长的时候,在model训练过程中对self-attention进行优化才会有比较明显的效果,正因如此,许多self-sttention的优化变形更多的是针对image的model
transformer
使用传统的self-attention的通用架构( Neural Network Architecture)
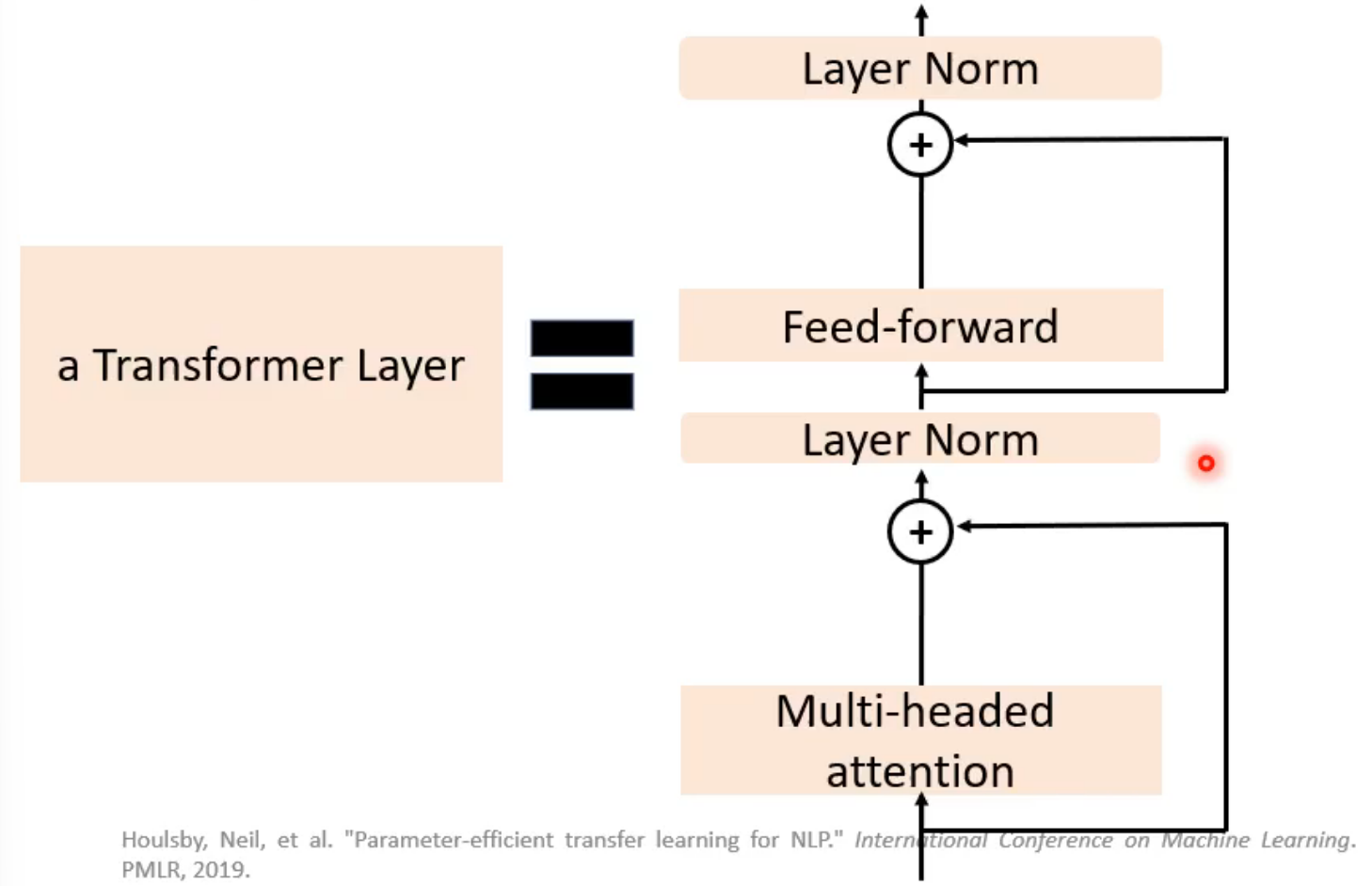
multi-head attention
从不同角度捕捉输入vector的特性,就是乘以不同的矩阵(W_Q、W_K)获得q、k
多种相关性 → 多个head → 多个q ……
- 位置资讯 → positional encoding:e_i加到vector上……
Local / truncated attention
只计算和左右邻居的关联性(类似CNN)
- stride attention:不一定是紧邻的邻居,可以跨一个、两个……
global attention
- 向sequence中加上special token,告诉model从剩余所有token中收集global information。非special token之间没有关联
- 直接将sequence中选一些token作为special token 或 添加两个
clustering
将k、q进行分类,同一类的说明attention大,对应的key和query的attention留下来,其余的忽略不计,直接看做0,从而简化计算
sinkhorn sorting network
使用另一个network来决定计算哪些地方的attention,将这个model练出来
linformer
只选择有代表性的key和q计算attention
- 使用CNN获取代表性key
synthesizer
直接使用network训练出 关联度α表
linear transformer
先算k、q → 先算v、k,减少计算量
attention-free
……
v.s. CNN
- CNN是简化版的Self-attention,recepted field不是人定的,像是机器自己学出来的
- Self-attention更flexible的CNN(model弹性大,sample数少的时候容易overfitting)
sequence-to-sequence
network
输入输出为序列,机器自己决定输出长度
deep learning
QA问题、翻译、语音识别、语法剖析、muti-label classification(一个sample由多个label)……
最好针对每种任务提供客制化模型
encoder-decoder结构
- 实现:RNN →(新) transformer
- 更像是一种学习的思路,具体实现使用transformer框架
encoder
- 输入一排向量 - block - 输出一排向量 *n
- positional encoding 加入位置信息
- block = self-attention - residual(将输入输出相加 作为输出,叫残差连接)- layer normalization - FC - residual - layer normalization
- 重复block,输出
decoder
Autoregressive - NT - 自回归model
- (以语音辨识为例)→ sentence completion
- 输入:encoder 的输出
- special token作为begin输入(one-hot-vector:00010000000),输出一个vector(长度为vocabulary - 单位),对vocabulary进行评分,输出max
- 重复,前一个的输出作为本次的输入
- decoder可以输出‘断’作为end
- 内部结构:
- masked-self-attention:先有a1,再有a2……,也就是说计算b2时,他是不知道a3、a4……,所以使用masked
- masked-self-attention - residual - layer normalization - FC - residual - layer normalization
- 流程
- cross attention:decoder会对encoder的输出做cross attention
- 输入:上一层decoder的输出 + encoder的输出
- decoder可以动态的关注encoder的输出的不同部分
- cross attention:decoder会对encoder的输出做cross attention
Non-Autoregressive - NAT
- 一次性并行生成整个序列,速度快
- 使用classification吃encoder的输出,预测长度x(一种方法)
- 给decoder输入x个begin,进而获得x长的输出,直接获得一整个句子
- 可以控制语音长度(控制x)
- 但performance不如NT
training
正确的字会被表示成一个one-hot-vector,我们希望model预测输出的vector和它越接近越好,即计算每个字的cross-entropy,总和越小越好(类似一个巨大的分类)
teacher forcing
training过程中,decoder的输入是正确答案**(不是前一个的输出),即让model知道:
1
2
3
4begin+机 → 器
begin+机+器 → 学
begin+机+器+学 → 习
begin+机+器+学+习 → end但实际过程中会有一个mismatch
tips
- copy mechanism(复制)
- 例如:chat-bot、摘要
- guided attention
- 要求model的attention是有固定方式的
- beam search
- greedy decoding不一定是最好的
- 但有时候根据任务的性质,我们不一定要最佳答案(比如需要model进行想象) → TTS(测试的时候加点noise)
- copy mechanism(复制)
testing
BLEU score:计算两个句子之间的score,越高越好
而training的过程中看的是loss-entropy
testing过程中,decoder看到的是自己的输出(可能是错的)
train和test的过程是不一致的!→ exposure bias
- scheduled sampling:training时也给decoder一些错误的东西 → 会影响平行化的能力

$ \text{ROUGE-N Recall} = \frac{\text{生成文本与参考文本重叠的 N-gram 数量}}{\text{参考文本中总的 N-gram 数量}} $
Self-Supervised learning
不需要label data训练model的方法
评价:
- GLUE任务集 - 文字,计算平均正确率,和人类比较
- SUPERB任务集 - 语音
auto-encoder
不需要label data
dimension reduction
old
- 输入:image vector
- 输出:image vector
- 高维输入 → encoder → 低维vector → decoder → 输出,二者越像越好
de-noising auto-encoder
先将输入add noise,之后auto-encoder,输出尽可能和没有noise的data一致
BERT
model
Non-Autoregressive 预测并行,但不能生成整个sequence,只是填空
340M parameters 参数量巨大
一般用于自然语言处理 text
干细胞
bert使用transformer实现的encoder + MLM(能看到前后的token)
- 输入:[CLS] + sequence + [SEP] + sequence
- 输出:一排vector00哦
pre-train(Self-Supervised learning)
手段:Masked language model(MLM)
将输入中的token随机遮住
将token用特殊符号mask取代
随机换成另外一个字
遮住的部分的输出做linear(乘以一个矩阵),经softmax输出概率分布,得到一个output → 这可以看做一个LM model(language model )
计算output与被盖住的正确答案minimize cross entropy
这个model可以看做在学习填空题,根据上下文学会了文字的含义(?)
- bert和linear要一起训练
实现
- 预测被覆盖token
- 判断两个sequence是否相连
fine-tune(semi-supervised)
细胞分化
bert(trained) + linear(需要training)
case1
- 输入:[CLS] + sequence
- 输出:class
取[CLS] 的输出
case2
- 输入:[CLS] + sequence
- 输出:same sequence
取sequence的输出
case3
Natural Language Inference
输入:[CLS] + sequence + [SEP] + sequence
输出:class(好坏、正误……)
取[CLS] 的输出
case4
Q&A,答案在文章中
- 输入:[CLS] + Q+ [SEP] + article
- 两个正整数i、j,答案就是在第i个到第j个token之间
任意取两个vector a、b
将article的输出与a进行内积,经softmax获得概率分布,概率最高点即为i
将article的输出与b进行内积,经softmax获得概率分布,概率最高点即为j
- 此时我们要训练的是随机选取的vector a、b
特性
cross-lingual
跨语言
multi-lingul bert
仅使用English Q&A pre-trained multi-lingul bert,test时发现model也能做中文的Q&A任务!
基础model是multi-lingul,理解一下就是这个model已经学会超多语言了
model让不同语言同一个意思的token的向量很接近(描述接近程度的指标 MRR)
但又能分清楚不同语言 → 不同语言相同意思的token的vector之间也有固定的偏移
cross-dicipline
跨学科
NLM 也可以读懂 DNA、蛋白质语言
- 将不同碱基对应到word上
- 输入进人类语言的bert model(比如英文填空题)中,linear得到output,不断update linear的参数
- 测试发现DNA种类预测正确率颇高
pre-trained的作用:
- optimization - loss下降快
- generalization - 举一反三的能力更强
speech Q&A
pre-training on artificial data
pre-train的过程中使得model学会了一些能力:???
pre-trained data:
- 成对的 - good
- 完全random - bad
- shuffle:连续编号随机打乱 - good
GPT
预测接下来的token是什么
异常大
使用transformer实现的decoder-Autoregressive Model 自回归模型,MLM(只能看到前面的token)
预测 → 实现生成任务
few-shot learning
- no gradient-desent
pre-trained language model (PLM) - advance
- example:bert、GPT、T5
problem & solution
现实中没有太多有label的data → data set 转换成 prompt 的形式
prompt tuning
将传统的分类任务转换成LM更擅长的填空任务;使用few-shot提高model的任务适配度,达到微调的目的
- 准备好prompt template:将data set转换成natural language prompt形式
- 用这些少量的data训练PLM填合适的mask,或者说 是将label与特定token进行对齐
- 最后通过 LM Head (linear+softmax)得到概率分布【不使用classification的model,因为他的训练是需要很多data+label的】,最高token转换为label
few-shot-learning
- prompt + demonstration
semi-supervised learning - PET
- 使用仅有的少量的label data训练prompt tune model
- 使用prompt tune model给unlabeled的data预测label,多重复几次,取概率和最大的作为pre-label
- 使用fine-tune去train model
zero-shot
- GPT-3
- multi-task
BIG,参数多,不同的task需要copy一个bert去fine-tune,时间长
- parameter-efficient
adapter
参数 = bert基准参数h + 对应某task专属的参数△h
- 在transformer中插入adapter
- adapter将h转变成△h

LoRA
- 在feed-forward前面插一个LoRA,LoRA生成△h
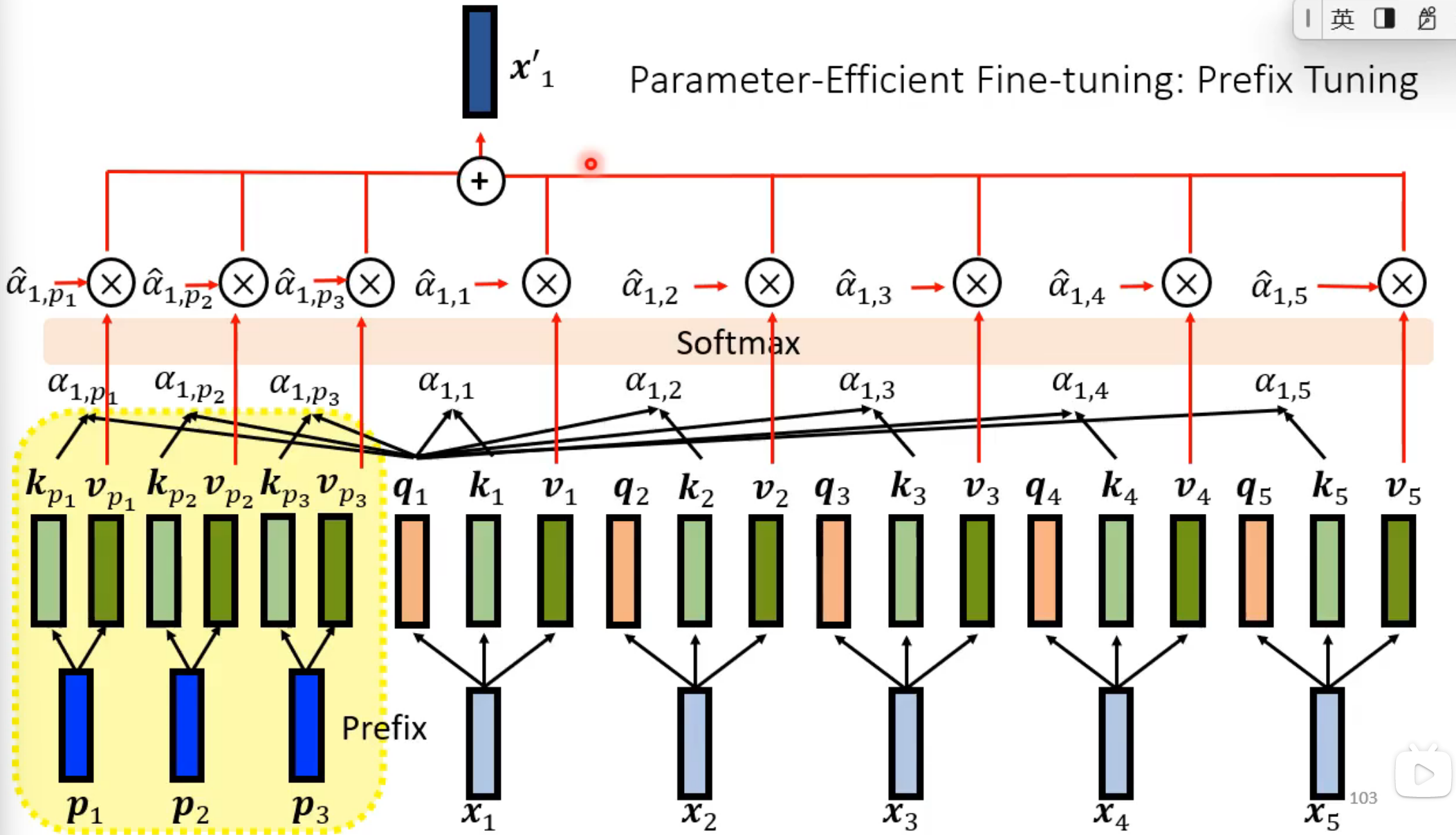
prefix tuning
- 在self-attention中加prefix,产生一个△h,加到原来的h上
- 训练prefix的值
soft prompting
- 直接在transformer的输入前插入prefix,训练prefix的值
- early exit
- reduce layers:在每一层加一个classifier,找到合适且正确的output,直接终止输出即可

For Speech data
- 输入:语音信号(vector)
- 输出:一排vector
bert
和文字处理基本一致:
- 先mask
- mask的长度要长
- mask所有向量的同一位置
- 拿到输出给到linear,让他恢复语音data
e.g.Mockingjay model
GPT
- 输入一段声音信号,model去预测下一段时间内的向量(长一点)
e.g.APC
改进
对于model来说,语音信号和图像的细节很多,相较于文字很难生成;
并且这些vector之间的差别很小,只是预测一个token对于model来说意义不大;
因此需要做一些改进
预测的东西尽可能长一点
predict simplified objects
- 将输入的声音vectors进行clustering(分类,也就是离散化)
- 当model进行预测时(填空or 预测下一段),输出类别id即可(相比生成一个vector更容易)
constrastive learning
实现:让相似的数据输出vector越近越好,不相似的越远越好
positive example
negative example
CPC
- 输入:音频向量
- 输出:vector
- output输入到predictor中,使用linear令输出与相邻的vector越像越好,与不同输入的vector越不像越好
wav2vec
- 输出:discrete离散的id/class
- discret可以消除杂讯
- 后面接一个bert的encoder(处理文字的bert输入就是离散的)
- 输出:discrete离散的id/class
wav2vec 2.0
- 语音的token很大,给的id很大,不宜使用classifier
bootstrapping approach - Data2vec
For Image
图像处理:
image → pixel像素 → 将pixel拉直成为向量
bert
GPT
改进
SimCLR
data augmentation(随机做变化 random cropping……)
形成positive和negative
augmentation程度控制比较重要
- 同一张图片data augmentation形成的图片就是positive
- 不同图片data augmentation形成的图片就是nagative
problem:选择negative example
解决:不再去挑选negative example
bootstrapping approach
选择两张positive,让他们产生的vector越接近越好
BYOL/SimSiam:teacher & student,student学一次后当做下一次的teacher
regularization
VICReg:variance-invariance-covariance
MoCo

explainable machine learning
linear model 解释能力强,但not powerful
deep model 很强大,但是不容易解释
decision tree,但没有完全解决问题
- local explanation (为什么你认为这张图片是cat
- global explanation(你认为什么样的东西是cat
local explanation
我们想知道model是根据那一部分推断出output的
- mask,计算输出正确answer的概率,据此知道model到底认识什哪一part
- 对vector的某一处加上△x,计算loss的变化△e;△e/△x → 画出saliency map,也可以看出model是根据哪一part做出的判断
通过这些方法我们知道有时model的learning会被杂讯干扰,比如model并不是通过cat的特征辨认而是通过其他内容(如背景、文字……),因此我们需要将杂讯去除掉
smoothGrad
- 对data添加random noisy,获得大量noisy data,计算平均saliency map
visualization
probing
探针
global explanation
我们想知道model在进行learning时到底在看哪些位置
create data
例如:
法1:我们想知道convolutional中filter1到底在做些什么,可以创造一个image X,令X的filter1评分和最大,此时观察这张X,就可以知道filter1重点观察识别什么东西
法2:也可以直接创造一张X,使得输出类别y的概率最大,但此时得到的X中有很多杂讯
法3:使用image generator输入z产生X,将X丢到image classifier(convolutional)中。依旧是找到合适的z,让输出类别y的概率越大越好,此时观察X。
outlook
让explanable model模仿复杂model的行为
Domain adaptation
training set 与 testing set 有一定的差异,我们希望model的performance依旧很好,我们希望model可以用在不一样的domain上
- source domain、target domain
basic idea
target domain large but non-labeled
feature extractor:不管输入来自哪个domain,输出是二者相似的部分,即过滤掉二者不同的部分
image → feature extractor → vector → label predictor → output
要求在vector处无法判断输入是来自哪个domain
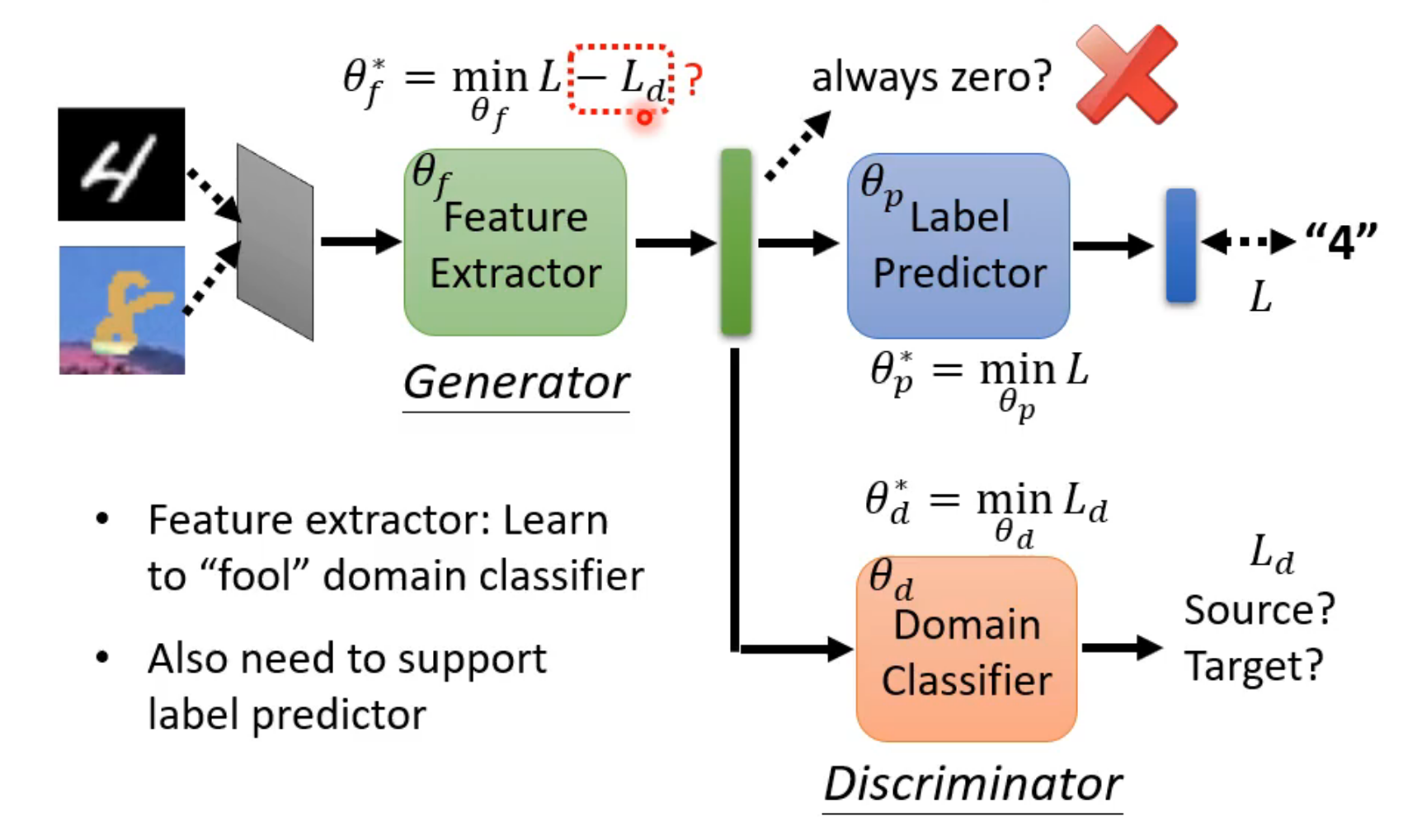
domain generalization
不知道新的domain
Reinforcement Learning
下面举例:game
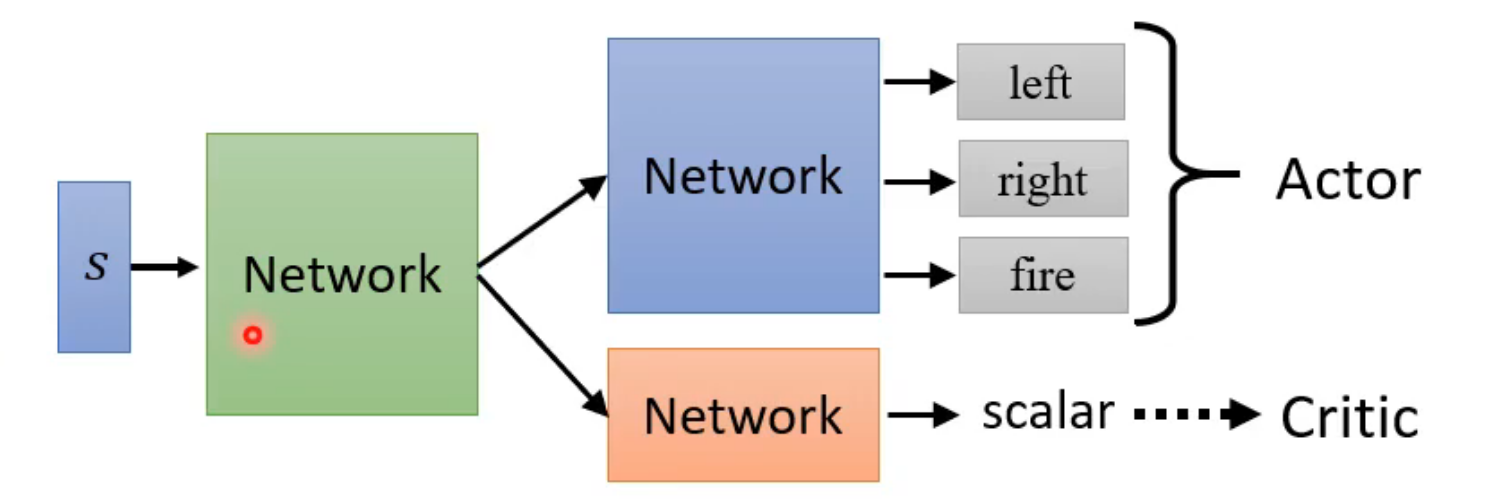
actor(Actor-Critic)
- 采取action
- 接受observation、reward
environment
- 接收action,调整,输出reward并提供observation
reward最大化
流程
actor(network = 复杂的function)
输入:image的pixel - transformer(实际上是游戏的参数)
输出:基于action的score进行随机sample
score计算:loss的大小(classifier)
- 想left,令 L_left 越小越好
- 不想left,令 -L_left 越小越好
但我们的“控制期望”一般不是binary的,所以我们给期望进行评分A_n
A为reward的总和(某种计算形式,不一定是简单的加和)
A 对应于 loss,取负号最小化即可
optimization
- 和 ML 有所不同(随机性很强)
- policy gradient
actor
针对A的计算方式
version1
- cumulated reward:将输入a后所有的reward加和
- 但如果整个过程很长,后面的reward可能并不归功于a的取值
version2
降低后期reward对当前A的影响
- 将输入a后计算所有的reward * r^(n-1)并加和
version3
好与坏是相对的,最终的A最好还是有正有负
- 所有的 A - b,减去baseline (normalization)
version3.5
version3中b的取值使用critic确定,
b=V_θ(s_t),即A = G’ - V_θ,
V_θ 指 actor 在 s_t 环境中,采取 输出的选择策略(一串评分或概率) 的G的均值
G’ 指 actor 在 s_t 中采取预测action的 reward总和
当A > 0:采取预测action的reward高于均值(随便sample出来的一个action),是一个好action
当A < 0:采取预测action的reward低于均值,是一个坏action
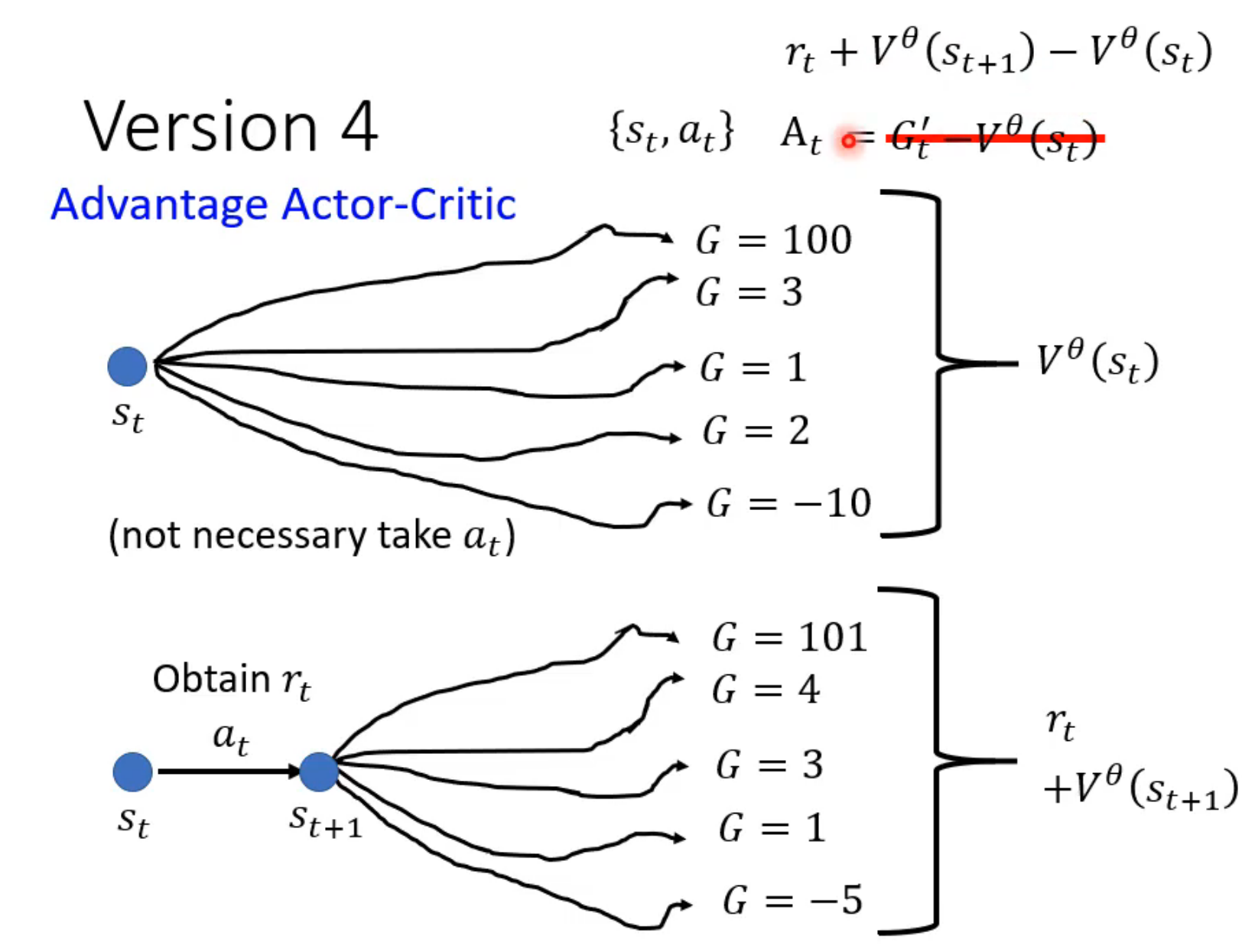
version4 - Advantage Actor-Critic
在version3.5中,G’是取了预测action后的一个sample的结果,而V取了整个选择策略的reward期望
可是采取了预测action后,也会有大量sample,也应该计算期望
(就是往前迈了一步
在s_t中采取预测action进入s_t+1,计算此时采取所有action的A的均值,也就是 critic 输入s_t+1的输出
V_θ(s_t+1)(if critic is good),此时在critic中计算得到的G' = r_t + V_θ(s_t+1)计算
A = r_t + V_θ(s_t+1) - V_θ(s_t)当A > 0:预测action的reward高于平均值,是一个好action
当A < 0:预测action的reward低于平均值,是一个坏action
Policy Gradient
采用 on-policy
off-policy 可以实现收集一次data,update多次参数
初始化actor参数(此时是一个随机的network)
training loop
资料收集在training阶段
令actor与环境交互,获取datas
计算 A_i
计算 Loss
θ_i = θ_i-1 - η▽Lupdate actor && exploration
actor要试图做些随机的事情,让training data多一点、不要太贪心,即令actor的输出根据分数随机化选择
在actor的参数上加noisy
……
critic
评估在某个environment中,actor采取它输出的选择策略后会得到多少cumulated reward(A)
critic评估的是actor的整体选择策略,带有期望意味
V_θ(s)
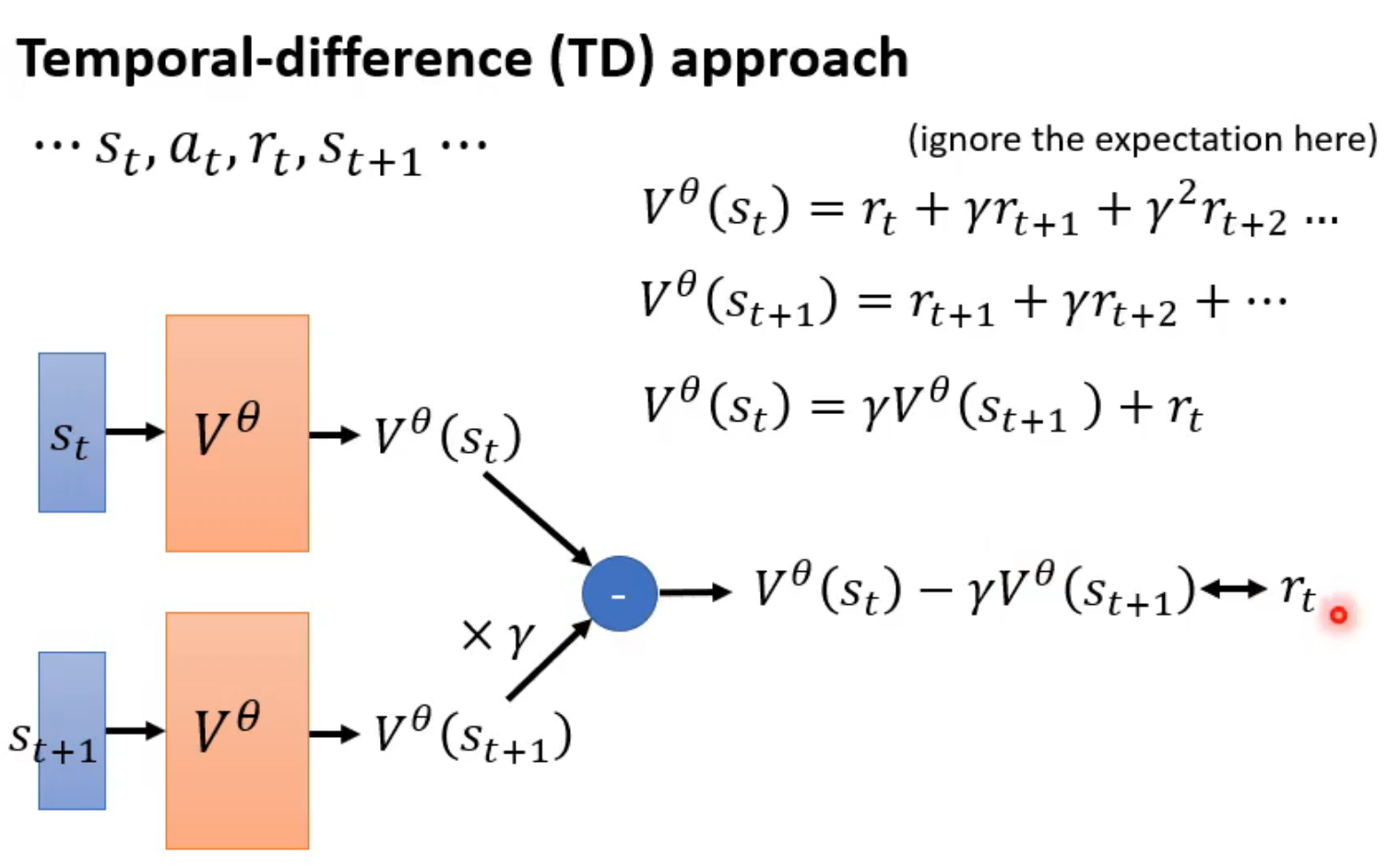
training method
MC
- actor与环境多互动几次
- critic的output 和 真实A大小越近越好
TD
training
tip
由于actor和critic的输入是一样的,这两个network的前部分会有一定的重叠,因此可以共用一部分network
reward shaping
想办法提供额外的reward,help network train (有种望梅止渴的感觉)
sparse reward
reward 几乎都是 0(可能action太多了,纯靠随机很难碰上有reward
(这就很难train了
额外增加reward,其实就是增加奖励机制,从而引导model往reward增加的方向走
比如game中: 捡到物资、活着 = reward++、空闲 = reward–
虽然这些并不会直接影响分数,但人通过这些domain knowledge可以引导model往对的方向走
curiosity
model看到新的有意义的东西,reward++
e.g.Mario game
no-reward
真实环境中的reward?自动驾驶……
人定reward,有时候会产生一些意想不到的questions
behavior cloning
比如:将人类的驾驶信息作为example给model
- problemS……
inverse reinforcement learning
reward function 是通过 expert 学出来的
输入:expert
输出:reward function
流程
- actor与environment互动,获得trajectories(轨迹)
- reward function,要求teacher的分数比actor高(一开始随机初始化function)
- 根据上面的reward function去train actor【Reinforcemnet learning】
- 更新actor,循环
很像GAN!
network compression
在一些资源有限的应用场景中,例如智能手表、无人机,本地资源无法承担 big model 的计算,而在云上计算又面临latency、privacy的问题,因此我们需要smaller model
软件层面
不互斥,可以同时采用
network pruning
将一些参数、neural剪掉
流程
train一个大的network
evaluate 参数重要性
remove 少量参数
fine-tune smaller network
循环
问题
以参数为单位:此时network变得不规则,反而无法加速,实做上比较难;but……
以neural为单位:比较好
- 如果直接train small network,正确率没有对大network剪枝得来的高,很难train起来
- 但将prune后的参数 随机初始化给small network,或者只给参数正负,值随机,就可以train起来
knowledge distillation
teacher network (large or much network)
student network (small)根据teacher学习
给teacher和student相同的输入,student根据teacher的输出进行training
student可以跟teacher学习到不同类别之间的关系,所以不直接让student学习正确答案
temperature for softmax(y/T)
将teacher的output变得平滑一些,给student提供更多信息
将teacher与student的每一层network分别对应train
应用:
ensemble:train model时会多train几个,最终的model取这些model的均值
实现:network参数做平均、直接output做平均
可以实现将多个ensemble model整合成一个
parameter quantization
less bit
weight clustering
- 相近的值看做一个群
huffman encoding
binary weight(防止overfitting)
Architecture design
I :通道数
O:输出通道数(filter数)
k*k:filter size
原始convolution
参数量:k*k*I*O
depthwise convolution
考虑同一个channel内部的关系,filter的数量就等于channel的数量
参数量:k*k*I
pointwise convolution
考虑不同channel的关系,1*1 filter
参数量:I*O
作比:depthwise + pointwise / 原始 < 1
类似 low rank approximation
在两层大小相差悬殊的network之间插一层,可以减小参数量
dynamic computation
希望一个network可以自由选择参数计算量
比如应对各种运算资源的情况
自由调整depth
- 在layer之间加一个extra layer,低电量时层数少些:training时evaluate一下中间层的输出loss
自由调整宽度
- train一个large network,训练过程中选择不使用的neural,evaluate loss,不断尝试
life long learning(LLL)
- 不同的任务:更像是不同domain相同的任务
catastrophic forgetting
问题
model 先学task1,再学task2,此时model会忘记task1的做法
但同时学习multi-task,model的两个task的正确率都很高
说明model是有能力同时学会两个task的
upper bound:multi-task training(太费劲了)
a model for each task:储存不了太多model
LLL v.s. transfer learning
- LLL关注旧的task做得如何
- transfer learning(fine-tune)关注新的任务做得如何
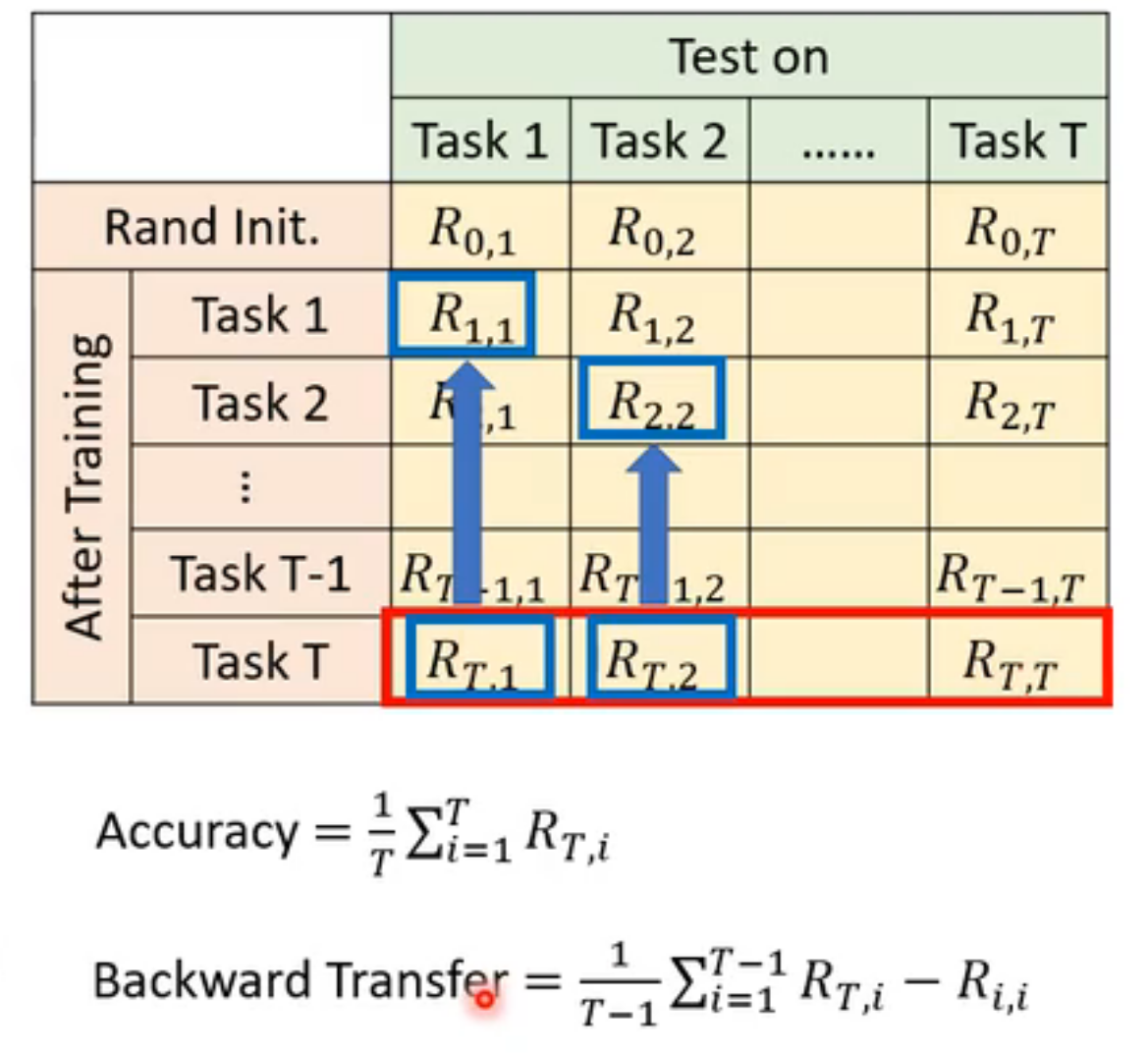
evaluation
准备 a sequence of tasks
- Accuracy
- backward transfer:一般是负的,描述学习完所有任务后,model对于任务T记住的程度
- forward transfer:在学习到对应任务T之前,对于任务T model已经学会了多少
method
selective synaptic plasticity
学习task2时只改变对于task1来说不重要的参数b_i
新loss计算时,除了包括正常的loss计算,还包括新参数与旧参数之间的loss
b_i指这个参数对于旧task是否重要:越大越重要,此时loss占比也变大
b_i 全为0:catastrophic forgetting
b_i 全为1:(固执)
b_i 可人为设定、直接算出来
- GEM:
- 在新task中更新参数的方向是旧task和新task更新方向的矢量和
- 需要一点点过去的资料
- GEM:
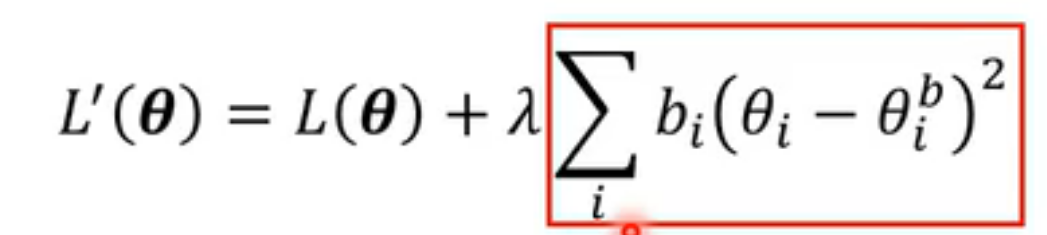
additional neural resource allocation
progress network
packnet
CPG
memory reply
- generator 生成所有旧task的data
curriculum learning
- 研究更好的task学习顺序
Meta learning
学习更新model参数
training
learn to learn
训练出一个F,它可以通过学会几个task从而学会这一类的task
e.g.我们用猫狗辨识、苹橘辨识任务训练F,之后F就能够生成能够完成各种各样辨识类任务的model
帮我们:调超参数Φ,在原来ML中都是人工调
cross-task training
trainingcross-task training
function:learning algorithm
元学习器
- F_Φ,自动调整model参数
- 输入:train task中train data
- 输入:train task中的train data
- 输出:model的参数 - 动态调整model参数
loss function:
L(Φ)
所有train task中test data的loss均值
直接评估classifier,从而间接评估F
optimization:
- gradient descent
- 如果微分不了,用reinforcement learning
- 反馈、循环
训练出一个F:learning algorithm
training过程中还需要development task评估F,防止其过拟合
- 使用development task计算loss,若开始上升,说明可能发生过拟合,应停止training
testing
cross-task testing
下面的整个过程称为episode
- 使用train task喂给F(learning algorithm),train出一个F
- 使用test task中的train set喂给F,F输出一个model
- 使用test task中的test set喂给model,得到output,evaluate output与真实结果
学习initialize
AML
reptile
学习optimize
学习训练network architecture
- 没办法微分 → reinforcement learning
- 输入:生成的network的accuracy
- 输出:network architecture的超参数
- environment:根据生成的参数建立network,进行within-task training
- maximize reward(-L)
还有data augmentation、sample reweighting、
v.s. self-supervised
- meta learning:学习如何更好的初始化
- self-supervised:也是在做初始化,有learning gap,但实做上效果好
将二者结合,使用bert给meta learning提供初始化参数
v.s.knowledge distillation
- knowledge distillation:teacher model的教学能力未知,最厉害的teacher不一定能教出最好的学生
- 在knowledge distillation过程中,让teacher model跟着student model的loss一起update,teacher model更新的目标是让student的正确率更高(teacher的正确率无所谓) → 例如用meta learning学习调temperature
v.s.domain generalization
- 输入:有很多training domain
- 输出:target domain(未知)
结合meta learning:
- 从training domain中挑一个domain假装是target,当做一个train task,收集many train task
- 训练learning algorithm
v.s.life long learning
- LLL:catastrophic forgetting
- 使用meta learning解决这个问题
Attacks
model功能受损、误导
white box
adversarial example敌对样本
benign良性输入 → transformation → 得到possible perturbations → constrains → search
goal
- non-targeted
- targeted
transformation
word level
同义词替换
vector距离近的word替换(counter-fitting GloVe embedding space)
bert,将要替换的word进行mask,bert进行预测,但这样也会输出语义相反的word
此时no-mask,会输出与之相近的word
语法方面
insertion
deletion
char level
image:
targeted:
- x与x0间的差距越大越好,与targeted x1间的差距越小越好
- x与x0的 L-infinity 小于阈值(肉眼看起来越像越好)
- FGSM:只需要update一次参数 → g中只有1与-1
black box
有training data
- 训练一个proxy model
无training data
- 使用teacher model的输入输出对训练proxy model
targeted attack难度比较大
one pixel attack
universal adversary attack
speech processing - 语音辨识
adversarial reprogramming
将一些任务寄生在model上
backdoor
训练资料上
defense
被动防御
输入data时,先加一个“盾牌”filter挡住attack signal
模糊化
压缩
过一遍generator
加各种随机的defence手段
主动防御
proactive defense
- adversarial training
先正常训练model,然后将training data变得具有攻击性,把这些data与正确label扔给model再进行训练,重复多次
会导致额外计算(solved)

- Author: dawn_r1sing
- Created at : 2025-04-07 20:07:05
- License: This work is licensed under CC BY-NC-SA 4.0.(转载请注明出处)